問題
解決策
製品等によって異なるが、Windows Ink機能を利用しない様に設定するとよい。
次の説明はCTH-661のためのもの。
その他
手書き入力パネルを無効にしたいと検索すると「Touch Keyboard and Handwriting Panel Service」を無効にすればよいと説明しているページが出てくるが、このサービスを無効にすると問題が発生する。
その名前に反してテキスト入力に結構深くかかわっているらしく、無効にすると日本語入力ができなくなる。
製品等によって異なるが、Windows Ink機能を利用しない様に設定するとよい。
次の説明はCTH-661のためのもの。
手書き入力パネルを無効にしたいと検索すると「Touch Keyboard and Handwriting Panel Service」を無効にすればよいと説明しているページが出てくるが、このサービスを無効にすると問題が発生する。
その名前に反してテキスト入力に結構深くかかわっているらしく、無効にすると日本語入力ができなくなる。
NextDNSを使って、特定の時間帯のみTwitterにアクセスできるように設定した。
深夜延々とツイッターを見てしまうということがある。人によってはTwitterでなくてYouTubeとかかもしれない。これをアクセス不可能にできればゆっくり眠れるのかなあと思うこともある。
特定の時間帯にアクセス不能にするというのは、DNSをカスタマイズすればできる。ただ、自分でDNSサーバーを立てるのは面倒だし、家のLAN/Wifi環境とそれ以外で統一的に利用できるようにするのは大変*1なので、なかなか難しい。
NextDNSというDNSサービスがあり、これは簡単にいうと自分で好きにカスタマイズできるDNSである。
この設定項目の中に「ペアレンタルコントロール」というものがあり、特定のサイトへのアクセスを制限でき、「娯楽時間」の設定で、接続を許可する時間を設定できる。
つまり、深夜帯以外を「娯楽時間」に設定することで、深夜はTwitterにアクセス不可にすることが可能だ。
また、システム全体に設定することで、家の中でも外でも同じDNSを使うことができる。
NextDNSは無料で30万クエリ/月まで利用でき、制限のないProプランだと250円/月となる。
まずは登録なしで一週間利用できるので試してみるといいのかもしれない。
以下、試してみたことと、感想を書いていく。
NextDNSのトップページを開き、“Try it now”ボタンをクリックするといきなりDNSサービスが準備される。
これをデバイスに設定すると利用準備が完了する。
NextDNSの設定ページの「セットアップガイド」に従って準備する。
「ペアレンタルコントロール」タブを開き、「ウェブサイト、アプリ、ゲーム」セクションで、アクセスを制限したいWebサイトやアプリを追加する。
「娯楽時間」セクションで時間を設定する。
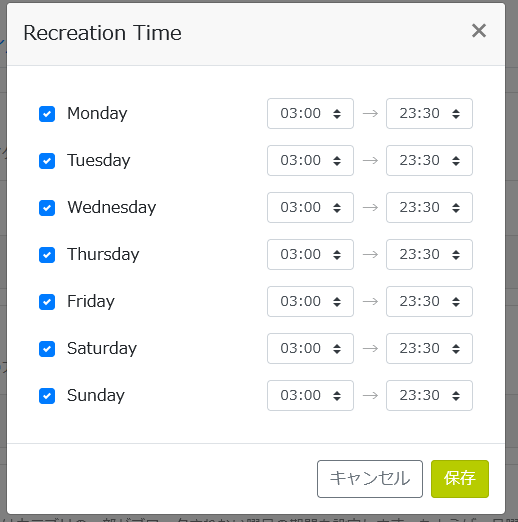
30分刻みでしか設定できないのと、終端の時間が23:30までしか設定できない、また複数時間帯を設定できないのが不便っぽい。
「ウェブサイト、アプリ、ゲーム」セクションで、設定したい項目の右の方にあるグレーの時計マーク🕓をクリックして有効化する。有効にすると緑色になる。
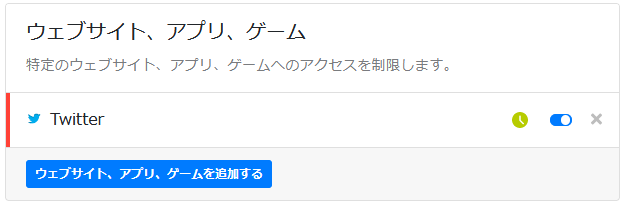
このままだと7日間で期限切れとなってまうので、継続して使用したければ登録する必要がある。
設定ページの上の「新規登録」ボタンを押すと登録画面に進むので、メールアドレスとパスワードを設定すればアカウントが作成される。
さて、DNSによる名前解決の結果は端末にキャッシュされる。
そのため、アクセス制限しても、それまでに通信していた場合にしばらくは繋がることになるかもしれない。
実際にAndroid端末でやってみると、しばらくはTwitterは普通に読み込みできる。10分ほどすると、TwitterのWebサイトにつながらなくなる一方、アプリでは次第に(キャッシュされてない)画像等が表示されなくなるもののテキスト情報の読み込みはできる。1時間ほどして確認してみたらアプリで新しいツイートが読み込めなくなっていた。
もう一度やってみたら遮断開始時刻から1分ほどで画像が読み込めなくなり、10分程度で完全に読み込めなくなった。
YouTubeアプリでやってみたら、制限して5分ほどしたら新しく再生を開始した動画の再生が止まるようになった。
というわけで、時間差はあるがそのうち効いてくるという感じっぽい。なるほど。
全体としては良い感じだと思うし、有用なケースはある。ただ、ペアレンタルコントロールの設定があまり柔軟でなく、もっと改善の余地があるなあと思った。
1次B-スプライン曲線(linear B-spline curve)とはすなわち折れ線のことである。
これはシンプルで、隣り合う2制御点を順番に直線で結んでいけば求める曲線(というか折れ線)が描ける。
一方で、2次B-スプライン曲線(quadratic B-spline curve)はB-スプライン基底関数という2次関数を使って制御点の影響を計算して曲線を描く。
基本的に2次B-スプライン曲線では、連続する制御点を結んだ折れ線、つまり直線の連続を描くことができない。
1次B-スプライン曲線の隣り合う2制御点の中点*1を制御点として2点間に挿入し、ノットベクトル(後述)を[0, 0, 0, 1, 1, 2, 2, 3, 3, 4, 4, 4]みたいにすると直線が表現できるが、制御点列としては別のものになる。
さて、ここで、1次B-スプライン曲線の制御点列をそのまま利用して、2次B-スプライン曲線で1次B-スプライン曲線を表現することはできるだろうか?
TrueTypeアウトラインの曲線部分は2次B-スプライン曲線の特殊な場合であるが、2次B-スプライン曲線は隣り合う2制御点を結ぶような折れ線、つまり1次B-スプライン曲線はふつう表現できない。そのため、TrueTypeアウトラインのcontourの制御点と2次B-スプライン曲線の制御点は同一ではないと考えていた。
一方で、もしそのような折れ線を2次B-スプラインで表現できるのであれば、直線部分も2次B-スプライン曲線として表現可能になり、任意のTrueTypeアウトラインは制御点を挿入することなしに2次B-スプライン曲線だと言えるのではないかと思う。
n次のB-スプライン曲線とは、制御点列(control points)とノットベクトル(knot vector)
で定義される曲線である。曲線の補間(制御点の影響の計算)にはn次のB-スプライン基底関数が用いられる。
n次のB-スプライン基底関数(n-th order B-spline basis function) は、次のように定義される。(コンピュータグラフィックス編集委員会(2004), p.66 (3.29)式)
これを使って、L個のセグメントからなるn次B-スプライン曲線は次のように定義される。
さてここで、1次B-スプライン曲線の場合を見ていく。
L個のセグメントからなる1次B-スプライン曲線は次のように定義される。
ここで、なる整数
に関して、点
と
で定義される一つのセグメント (
)だけをみると、
ここで、B-スプライン基底関数は次のようになる。
したがって、
というわけで2点間の線形補間になっている=直線であることがわかる。
さて、次に2次B-スプライン曲線の場合について考える。
2次B-スプライン曲線の1つのセグメントは3点の制御点からなる。そのため、1次B-スプライン曲線と同じ数のセグメントを用意するためには、制御点を最後に一個追加しないといけない。
L個のセグメントからなる2次B-スプライン曲線は次のように定義される。
ここで、なる整数
について、点
と
,
で定義される一つのセグメント
だけをみると、
となる。
プログラムを使って描いてみた。さすがに無限大は扱えないので適当に大きな値にしてみる。
描画に用いたPython3コードを次に示す*4。STEPが公比rに相当する。
gist.github.com
赤が正解となる1次B-スプライン曲線、黒が2次B-スプライン曲線である。
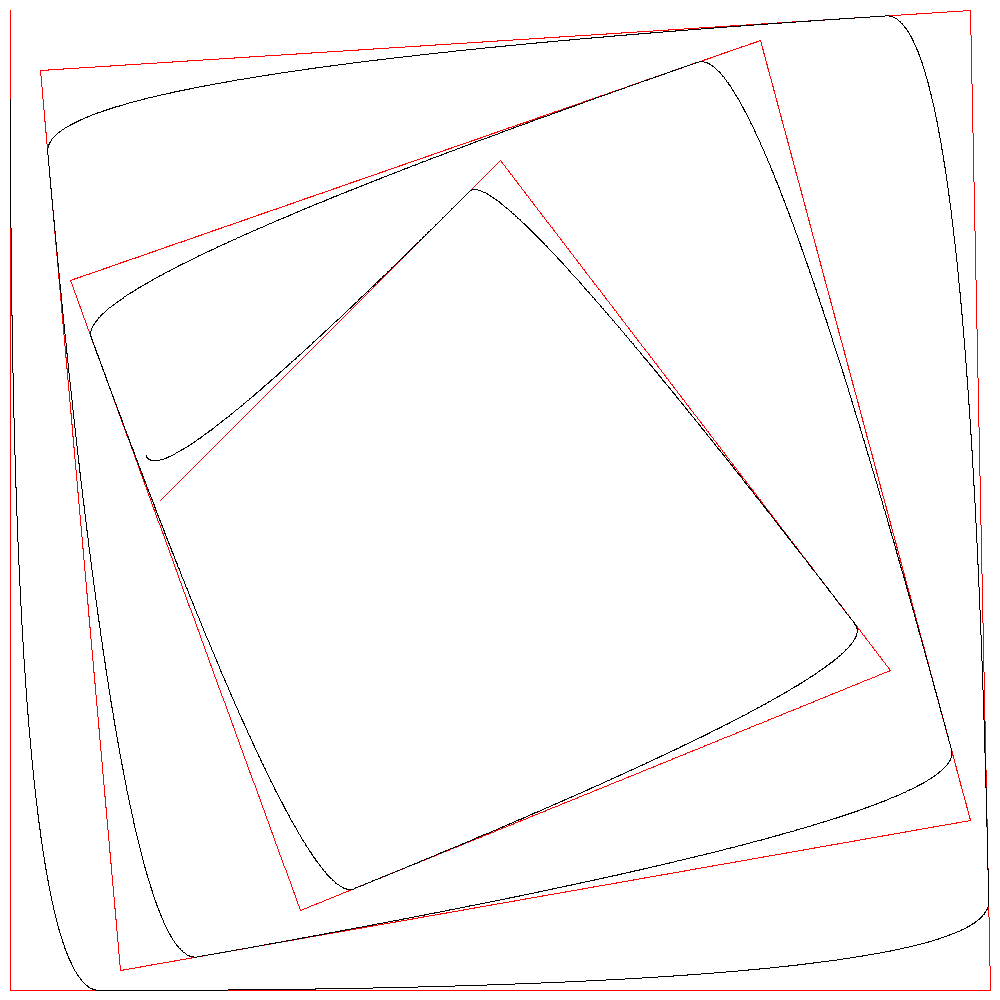
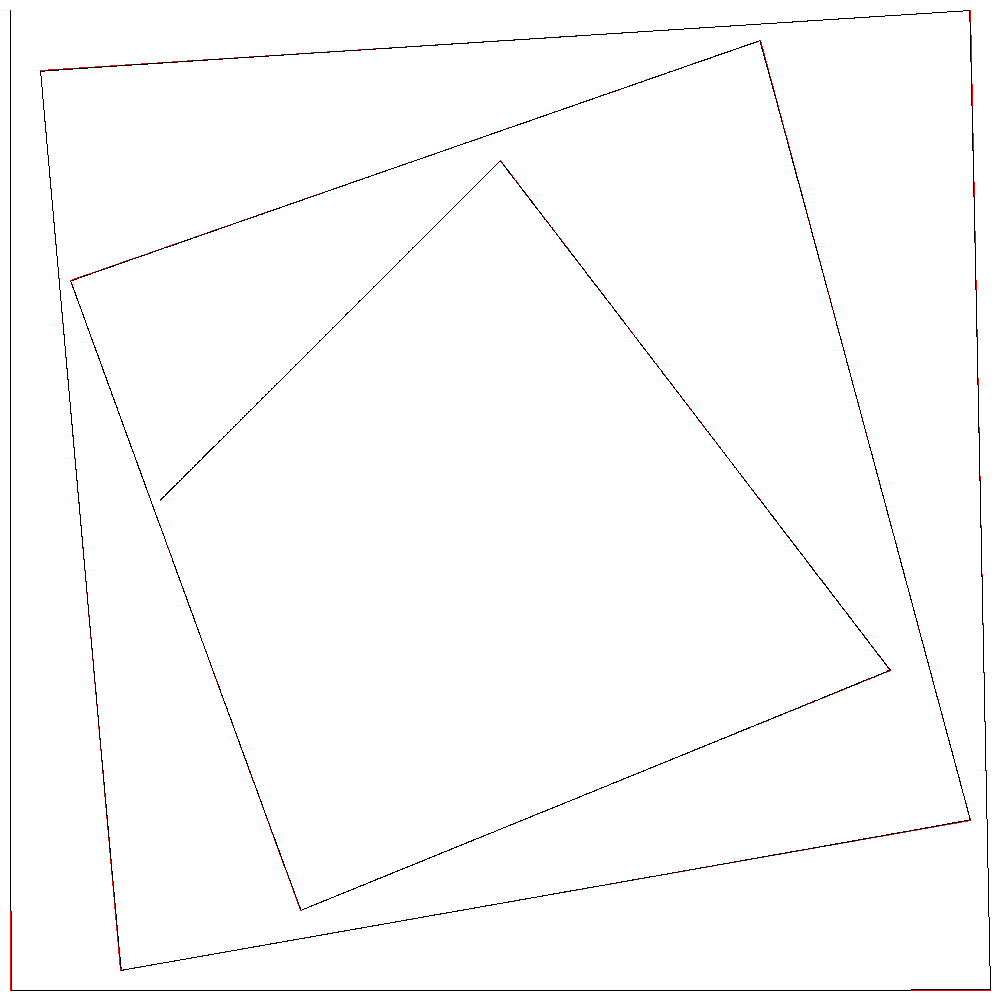

r=10000でほぼ一致している。
隣り合う2制御点をr:1で内分する点を通る曲線が描かれているので、r=10000のときは2点を10000:1に内分する点を通る曲線となる。誤差が1ピクセルより小さくなるので直線に見えるというわけである。
画像サイズが(1000, 1000)なので公比r=10000程度でも直線になっているが、ドローソフトで線を拡大していく場合などはそれでも足りなくなると思う。
r=10000の場合、制御点15個に対して最初のノット値と最後のノット値を比べると1064倍になっている。複雑な図形にしたらすぐにあふれそう。
1次B-スプライン曲線を(制御点を変更せずに)2次B-スプライン曲線を使って表現できる(そのようなノットベクトルの取り方が存在する)ことがわかった。
つまり、適切にノットベクトルを用意すれば、TrueTypeアウトラインのcontourをそのまま2次B-スプラインを用いて描画可能なのでは?
というわけで試してみる。
用意するのは次の制御点列。onはTrueTypeにおけるon-curve点、offはoff-curve点を示す。
| idx | 座標 | on/off |
|---|---|---|
| 0 | (10, 10) | on |
| 1 | (10, 990) | on |
| 2 | (250, 500) | off |
| 3 | (500, 990) | off |
| 4 | (750, 500) | off |
| 5 | (990, 990) | on |
| 6 | (990, 10) | on |
| 7 | (500, 500) | off |
| 8 | (10, 10) | on |
これに対して、
みたいなノットベクトルを用意してみたらどうだろう。
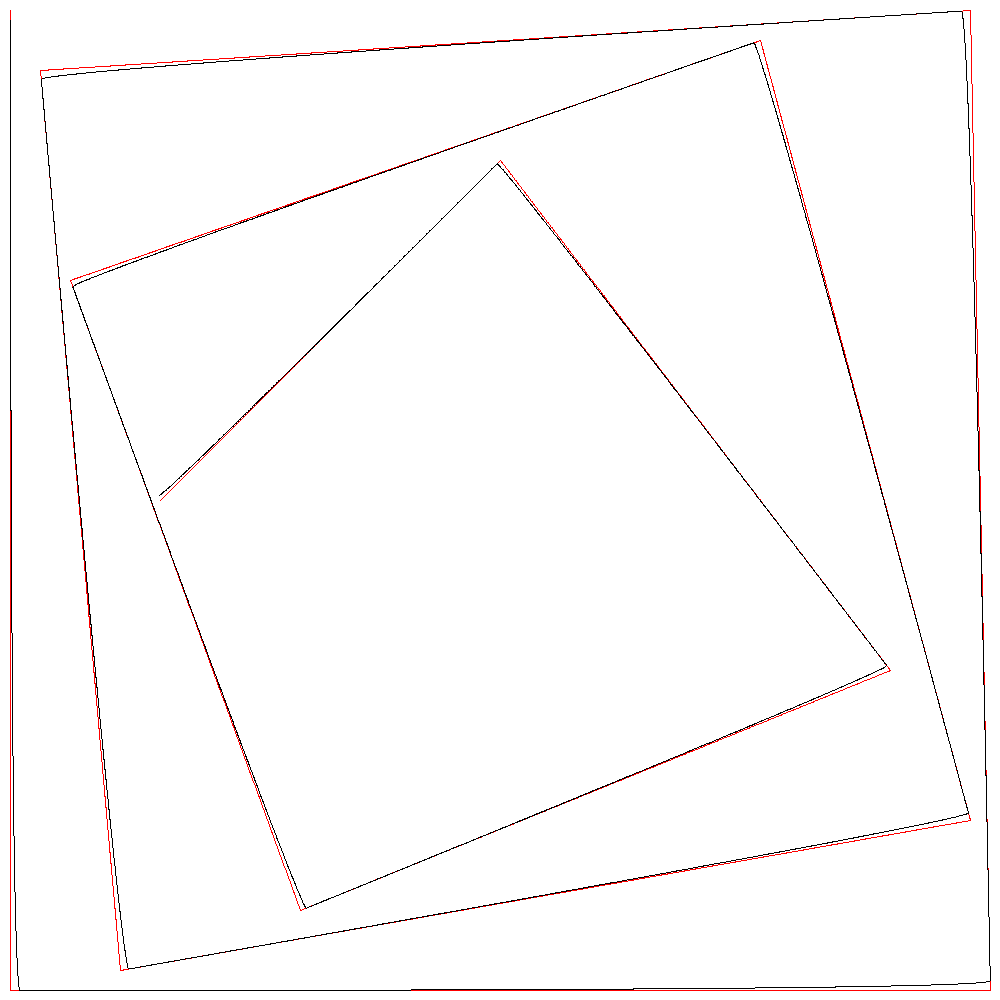
r=10000として計算したのが次の画像である。この手法で計算された曲線が黒い線となっている。

制御点を青の点で示している。制御点列を結んだ直線が水色の直線である。
赤は正解となる2次B-スプライン曲線で、2連続するon-curve点の途中にその2点の中点をoff-curveな制御点として挿入してon-curve点の連続をなくし、ノットベクトルを[0, 0, 0, 1, 1, 2, 3, 4, 4, 5, 5, 6, 6, 6]としたものであるが、黒い線の下に入ってほぼ見えなくなっている。
描画に使用したPython3コードは次のものである。
というわけで、こんな感じのわけわからんノットベクトルを用意すれば、同一の制御点列を用いつつも2次B-スプライン曲線はTrueTypeアウトラインのcontourに一致する気がする*5。
ちゃんと計算すれば(上でやったのと同じような議論で)示せると思うけど面倒なので気になったら各自計算してね…
無限大を導入すれば、任意のTrueTypeアウトラインのcontourの制御点列をそのまま2次B-スプライン曲線の制御点列として、同一のアウトラインを描けるノットベクトルの取り方が存在しそう、ということがわかった。無限大を導入すれば……
コンピュータで扱う数値計算に無限大を導入するな💢
実用としては素直に直線で計算するべし。
PostgreSQLの実行でタイムアウトしていたので、VACUUM ANALYZEを実行したら解決した。
以前Pleromaのサーバを移行したが、
その後、多少問題はあったが普通に動いていた。
環境はPleroma 2.3.0で、ソースからインストールしたものである。
しかし、今日急に、SubwayTooterでホームタイムラインを取得しようとした(GET /api/v1/timelines/home)場合に、500 Internal Server Errorが返ってくるようになった。(ブラウザからは普通に見れていたのでよくわからない…)
さてどうしたものか。
サーバーにログインし、
sudo journalctl -fu pleroma.service
実行する。するとpleromaのログが流れてくる。
ここでSubwayTooterでホームタイムラインを取得しようとすると、次のようなログがでてくる。時刻やrequest_idなど先頭部分は省いている。
[info] GET /api/v1/timelines/home
[error] Postgrex.Protocol (#PID<■■■>) disconnected: ** (DBConnection.ConnectionError) client #PID<■■■> timed out because it queued and checked out the connection for longer than 15000ms
#PID<■■■> was at location:
:prim_inet.recv0/3
(postgrex) lib/postgrex/protocol.ex:2838: Postgrex.Protocol.msg_recv/4
(postgrex) lib/postgrex/protocol.ex:1880: Postgrex.Protocol.recv_bind/3
(postgrex) lib/postgrex/protocol.ex:1735: Postgrex.Protocol.bind_execute_close/4
(db_connection) lib/db_connection/holder.ex:316: DBConnection.Holder.holder_apply/4
(db_connection) lib/db_connection.ex:1272: DBConnection.run_execute/5
(db_connection) lib/db_connection.ex:1359: DBConnection.run/6
(db_connection) lib/db_connection.ex:613: DBConnection.execute/4
[error] Internal server error: %DBConnection.ConnectionError{message: "tcp recv: closed (the connection was closed by the pool, possibly due to a timeout or because the pool has been terminated)", reason: :error, severity: :error}
[info] Sent 500 in 15293ms
[error] #PID<■■■> running Pleroma.Web.Endpoint (connection #PID<■■■>, stream id 1) terminated
Server: nixeneko.info:80 (http)
Request: GET /api/v1/timelines/home?limit=80
** (exit) an exception was raised:
** (DBConnection.ConnectionError) tcp recv: closed (the connection was closed by the pool, possibly due to a timeout or because the pool has been terminated)
(ecto_sql) lib/ecto/adapters/sql.ex:593: Ecto.Adapters.SQL.raise_sql_call_error/1
(ecto_sql) lib/ecto/adapters/sql.ex:526: Ecto.Adapters.SQL.execute/5
(ecto) lib/ecto/repo/queryable.ex:192: Ecto.Repo.Queryable.execute/4
(ecto) lib/ecto/repo/queryable.ex:17: Ecto.Repo.Queryable.all/3
(pleroma) lib/pleroma/pagination.ex:40: Pleroma.Pagination.fetch_paginated/4
(pleroma) lib/pleroma/web/activity_pub/activity_pub.ex:1172: Pleroma.Web.ActivityPub.ActivityPub.fetch_activities/3
(pleroma) lib/pleroma/web/mastodon_api/controllers/timeline_controller.ex:59: Pleroma.Web.MastodonAPI.TimelineController.home/2
(pleroma) lib/pleroma/web/mastodon_api/controllers/timeline_controller.ex:5: Pleroma.Web.MastodonAPI.TimelineController.action/2ここから、PostgreSQLで時間がかかっていることがわかる。
検索してたら次の投稿を見つけた。
pleroma.gidikroon.eu
I think I remember that once after a migration I needed to do an ANALYZE to stop the timeouts from happening.
そのため、データベースのVACUUM ANALYZEを実行してみた。
cd /opt/pleroma sudo service pleroma stop sudo -Hu pleroma MIX_ENV=prod mix pleroma.database vacuum analyze sudo service pleroma start
参考: Database maintenance tasks - Pleroma Documentation
vacuum analyzeの直前にpg_dumpでバックアップをしている。pleromaはデータベース名、pleroma_database_backup.pgdumpは出力ファイル
sudo -Hu postgres pg_dump -d pleroma --format=custom -f pleroma_database_backup.pgdump
すると、ホームタイムラインが復活した。
副作用として、うまく動かなくなっていたパブリックタイムラインとハッシュタグタイムラインが動くようになった。
データベースを移行した時とか、定期的にVACUUM ANALYZEを実行するといいようだ。
Python 3で、長い文字列を格納した文字列変数に+=で連結して文字列を保持していると遅い。
文字列のリストとして保持しておいて最後に連結すると速い。
擬似コードでは
# text_iterは文字列を返すiterableオブジェクト #遅い out_text = "" for text in text_iter: out_text += text #速い out_list = [] for text in text_iter: out_list.append(text) out_text = "".join(out_list)
Python 3で、テキストファイルを読み込んで、指定の条件に合致した行だけ取り出すというプログラムを書いていた。だが、どうにも実行が遅い。
そのコードでは、ループで行を取り出し、それを文字列変数に+=で結合して保持して、最後にファイルに書き込んでいた。
もしかして、文字列の連結がよくないのでは?と思ったので実験してみた。
沢山の行が含まれるテキストを、各行ごとにループを回し、行の文字列を変数に蓄積していくというプログラムを考える。
一行ずつループを回して、結果を格納していくが、
"".joinで連結して文字列にするという2つの方法が考えられる。この2つを比較してみる。
テストに使ったテキストはhttps://dumps.wikimedia.org/jawiki/20210720/のjawiki-20210720-all-titles.gzを解凍したもので、90MB程度、3778098行ある。これと同じディレクトリに次のpythonコードを入れて実行する。
コードを示す。
# coding: utf-8 import codecs import time TEXTFILE = "jawiki-20210720-all-titles" REPORT_INTERVAL = 100000 if __name__ == '__main__': print("Start Processing...") out_text = "" with codecs.open(TEXTFILE, "r", "utf-8") as f: lines = f.readlines() # 1. start_time_1 = time.time() n_processed = 0 out_text = "" for line in lines: out_text += line n_processed += 1 if n_processed % REPORT_INTERVAL == 0: print(n_processed, "lines processed") elapsed_1 = time.time() - start_time_1 print(len(out_text)) # 2. out_list = [] n_processed = 0 start_time_2 = time.time() for line in lines: out_list.append(line) n_processed += 1 if n_processed % REPORT_INTERVAL == 0: print(n_processed, "lines processed") out_text = "".join(out_list) elapsed_2 = time.time() - start_time_2 print(len(out_text)) print("str_concat:", elapsed_1, "sec") print("list:", elapsed_2, "sec")
これを実行する。
それで、最初に文字列の結合によるものをやっているが、出力の間隔を見ているとどんどん遅くなっていくのが分かる。
最後に出力される結果を見ると、
str_concat: 519.9358415603638 sec list: 0.746680736541748 sec
…うそやろ!?…となっていて、378万回弱の文字列の連結は8分以上かかっている一方、リストへの追加は1秒未満で終わっていることがわかる。その差約700倍…
実験した環境は、
である。
ちなみに、同じPCでCygwin上のPython 3.8.9で実行した場合は
str_concat: 93.5771963596344 sec list: 0.7298173904418945 sec
とかで、それでも100倍以上の差はある。
文字列の+による連結は非破壊的操作なので、毎回結合後の文字列全体を新しい値として生成してメモリに格納してるので遅いということなのかなと思う。
list.appendは破壊的操作なので、新しく追加する部分だけ処理すればいいので速い。
長いテキストを処理するときに、処理後のテキストを保持するのには、連結して文字列で保持すると遅く、文字列のlistで保持して後で"".joinした方が速い。
Windows 10上のAnacondaに、TensorFlowのバージョン2.3.0, 2.4.1, 2.5.0のGPUサポート付きのものを、仮想環境ごとに併用可能な状態でインストールする。
TensorFlowを導入しようとしてめんどくせ~って思ったのでインストール方法をメモしておく。
ディープラーニングライブラリごとに、またバージョンごとに、GPUサポートに必要とするCUDAのバージョンが異なっている。しかし、環境変数に同時に複数のバージョンのCUDAをPathに設定することはできない(複数設定しても一つしか参照されないので意味がない)。
そのため、仮想環境ごとにPathを変更したコマンドプロンプトを起動できるようにしたらいいのでは?と思った。これをすることで、違うバージョンを併用できる。
以下では、TensorFlowのバージョン2.3.0, 2.4.1, 2.5.0のGPUサポート付きのものを、仮想環境ごとに併用可能な状態でインストールする方法を書く。
TensorFlowは、そのバージョンごとに、動作が確認されているPython, CUDAとcuDNNのバージョンがある。これに従うことで、CUDA等のバージョンに関連する問題を防ぐことができる。
テストされたPython, CUDA, cuDNNのバージョンは次のページで確認できる。
TensorFlowのバージョンごとにPython, cuDNN, CUDAのバージョンが書かれているので、それを使うようにする。
ここではtf230gpuという名前の仮想環境を作成する。TensorFlow 2.3.0はPython 3.5-3.8に対応しているようなので3.8を使うことにする。
Anaconda Promptを起動し、次のコマンドを実行する。
conda create -n tf230gpu python=3.8
Anaconda Promptから、仮想環境をtf230gpuに切り替える。
activate tf230gpu
その後、tensorflow-gpuのインストールを行う。
conda install tensorflow-gpu=2.3 tensorflow=2.3=mkl_py38h1fcfbd6_0
tensorflow=2.3=mkl_py38h1fcfbd6_0は本来要らないはずだが、これについてWindows 10ではビルドの自動選択にバグがあるっぽくて、ビルドを指定してインストールしないとGPUが使えない。
CUDA, cuDNNも一緒にインストールしてくれるので楽。
インストールが終わったら、
python
を実行し、
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
とか入力して、GPUが認識されているか試してみる。device_typeがGPUやXLA_GPUなどになっているデバイスがリストアップされていればOK。
仮想環境が、Anacondaのインストールディレクトリの下のenvs\tf230gpuにあるので、Scripts\activate.datにこれを指定して起動すると、仮想環境に切り替わった状態になるらしい。
Windowsのスタートメニューの「Anaconda Prompt (anaconda3)」を右クリック→「ファイルの場所を開く」を選択し、開いたフォルダのAnaconda Prompt (anaconda3)のショートカットをコピーし、デスクトップとかに貼り付ける。
貼り付けたショートカットの名前をAnaconda tf230gpuとかの分かりやすい名前に変えておく。
貼り付けたショートカットの右クリックメニューから「プロパティ」を開き、「リンク先」の最後を
C:\Users\USERNAME\anaconda3→C:\Users\USERNAME\anaconda3\envs\tf230gpu
のように変更し、
%windir%\System32\cmd.exe "/K" C:\Users\USERNAME\anaconda3\Scripts\activate.bat C:\Users\USERNAME\anaconda3\envs\tf230gpu
のようにする。ここで、USERNAMEはWindowsのユーザー名で、環境により異なる。
これで、このショートカットをダブルクリックして起動すると、TensorFlow 2.3.0をインストールした仮想環境に切り替わるようになる。
tensorflow-2.4.0のテスト済みバージョンは
なので、CUDA Toolkit 11.0 Update1とcuDNN v8.0.5 (November 9th, 2020), for CUDA 11.0を入れるといいと思う。
CUDAは、CUDA Toolkitをダウンロードしてきて、実行ファイルを実行し、指示に従えばインストールされる。
cuDNNは、ダウンロードしてきた圧縮ファイルのcudaフォルダの中身を、CUDAのインストール先C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\以下に突っ込むとよい(手抜き)
その後、環境変数のPathからCUDAのパスを削除する(しなくても問題ないが、他で使わないので…)。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\binC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\libnvvp仮想環境tf241gpuを作成する。
conda create -n tf241gpu python=3.8
Windowsのスタートメニューの「Anaconda Prompt (anaconda3)」を右クリック→「ファイルの場所を開く」を選択し、開いたフォルダのAnaconda Prompt (anaconda3)をコピーしてデスクトップかどこかに貼り付ける。
ショートカットを右クリック→「プロパティ」を開き、から開いたプロパティから「リンク先」をメモする。
デフォルトでインストールすると「リンク先」は次のようになっていると思う。ユーザー名の部分USERNAMEはそれぞれの環境で異なるので、以下適切に読み替える。
%windir%\System32\cmd.exe "/K" C:\Users\USERNAME\anaconda3\Scripts\activate.bat C:\Users\USERNAME\anaconda3
ここでは、C:\Users\USERNAME\anaconda3\Scripts\activate.batがコマンドプロンプト起動時に実行されるバッチファイル、C:\Users\USERNAME\anaconda3がAnacondaのインストールディレクトリとなっている。
ここで、Anacondaのインストールディレクトリ以下のところに、
C:\Users\USERNAME\anaconda3\Scripts\activate_tf241gpu.batを次の内容で作成する。USERNAMEは(というか、仮想環境のパスは)適切なものに置き換える。
@set PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\bin;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\extras\CUPTI\lib64;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0\include;%PATH% @set CUDA_PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0 @CALL "%~dp0activate.bat" C:\Users\USERNAME\anaconda3\envs\tf241gpu
@は、コマンドの最初につけるとechoを抑制する。Pathを設定した後、仮想環境を指定してアクティベート用のバッチファイルを呼び出している。
先ほど貼り付けたショートカットを右クリック→「プロパティ」から、リンク先を
%windir%\System32\cmd.exe "/K" C:\Users\USERNAME\anaconda3\Scripts\activate_tf241gpu.bat
のように変更し、OKを押して閉じる。ショートカットの名前をAnaconda tf241gpuとかの分かりやすい名前に変えておくとよい。
これで、このショートカットをダブルクリックして起動すると、CUDAをPathに設定した上で、さっき作成した仮想環境に切り替わるようになる。
tensorflow-2.5.0のテスト済みバージョンは
なので、CUDA Toolkit 11.2.2とcuDNN v8.1.1 (Feburary 26th, 2021), for CUDA 11.0,11.1 and 11.2を入れるといいと思う。
CUDAは、CUDA Toolkitをダウンロードしてきて、実行ファイルを実行し、指示に従えばインストールされる。
cuDNNは、ダウンロードしてきた圧縮ファイルのcudaフォルダの中身を、CUDAのインストール先C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\以下に突っ込むとよい(手抜き)
その後、環境変数のPathからCUDAのパスを削除する(しなくても問題ないが、他で使わないので…)。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\binC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\libnvvpWindowsのスタートメニューの「Anaconda Prompt (anaconda3)」を右クリック→「ファイルの場所を開く」を選択し、開いたフォルダのAnaconda Prompt (anaconda3)をコピーしてデスクトップかどこかに貼り付ける。
ショートカットを右クリック→「プロパティ」を開き、から開いたプロパティから「リンク先」をメモする。
デフォルトでインストールすると「リンク先」は次のようになっていると思う。ユーザー名の部分USERNAMEはそれぞれの環境で異なるので、以下適切に読み替える。
%windir%\System32\cmd.exe "/K" C:\Users\USERNAME\anaconda3\Scripts\activate.bat C:\Users\USERNAME\anaconda3
ここでは、C:\Users\USERNAME\anaconda3\Scripts\activate.batがコマンドプロンプト起動時に実行されるバッチファイル、C:\Users\USERNAME\anaconda3がAnacondaのインストールディレクトリとなっている。
ここで、Anacondaのインストールディレクトリ以下のところに、
C:\Users\USERNAME\anaconda3\Scripts\activate_tf250gpu.batを次の内容で作成する。USERNAMEは(というか、仮想環境のパスは)適切なものに置き換える。
@set PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\bin;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\extras\CUPTI\lib64;C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\include;%PATH% @set CUDA_PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2 @CALL "%~dp0activate.bat" C:\Users\USERNAME\anaconda3\envs\tf250gpu
@は、コマンドの最初につけるとechoを抑制する。Pathを設定した後、仮想環境を指定してアクティベート用のバッチファイルを呼び出している。
先ほど貼り付けたショートカットを右クリック→「プロパティ」から、リンク先を
%windir%\System32\cmd.exe "/K" C:\Users\USERNAME\anaconda3\Scripts\activate_tf250gpu.bat
のように変更し、OKを押して閉じる。ショートカットの名前をAnaconda tf250gpuとかの分かりやすい名前に変えておくとよい。
これで、このショートカットをダブルクリックして起動すると、CUDAのディレクトリをPathに追加した上で、さっき作成した仮想環境に切り替わるようになる。
Windows 10上で、Anacondaでtensorflow-gpu 2.3.0をインストールしたが、GPUが認識されなかった。ビルドの自動選択に不具合があるらしく、インストール時にビルドを指定すると問題なく認識されるようになった。
現在、AnacondaのcondaコマンドでインストールできるTensorFlowは2.3.0が最新っぽい。
普通であれば、次のコマンドでGPU版のTensorFlowがインストールできるはずである。
conda install tensorflow-gpu==2.3.0
しかし、Windows 10環境で、上のコマンドでインストールした場合に、pythonで
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
を見てみると、GPUやXLA_GPUなどのdevice_typeをもつものが表示されず、GPUを認識していないようだった。
なぜかWindows 10のAnacondaのTensorFlow 2.3.0において、ビルドの自動選択がうまく動いていないらしい。
そのため、ビルドを自分で指定してやるとうまくインストールできる。
Python 3.8をインストールする場合、conda install tensorflow-gpu==2.3.0の代わりに
conda install tensorflow-gpu=2.3 tensorflow=2.3=mkl_py38h1fcfbd6_0とするといいらしい。例えば次のようなコマンドになる。
conda create -n tf230gpu python=3.8 conda activate tf230gpu conda install tensorflow-gpu=2.3 tensorflow=2.3=mkl_py38h1fcfbd6_0
