問題提起
1次B-スプライン曲線(linear B-spline curve)とはすなわち折れ線のことである。
これはシンプルで、隣り合う2制御点を順番に直線で結んでいけば求める曲線(というか折れ線)が描ける。
一方で、2次B-スプライン曲線(quadratic B-spline curve)はB-スプライン基底関数という2次関数を使って制御点の影響を計算して曲線を描く。
基本的に2次B-スプライン曲線では、連続する制御点を結んだ折れ線、つまり直線の連続を描くことができない。
1次B-スプライン曲線の隣り合う2制御点の中点*1を制御点として2点間に挿入し、ノットベクトル(後述)を[0, 0, 0, 1, 1, 2, 2, 3, 3, 4, 4, 4]みたいにすると直線が表現できるが、制御点列としては別のものになる。
さて、ここで、1次B-スプライン曲線の制御点列をそのまま利用して、2次B-スプライン曲線で1次B-スプライン曲線を表現することはできるだろうか?
モチベーション
TrueTypeアウトラインの曲線部分は2次B-スプライン曲線の特殊な場合であるが、2次B-スプライン曲線は隣り合う2制御点を結ぶような折れ線、つまり1次B-スプライン曲線はふつう表現できない。そのため、TrueTypeアウトラインのcontourの制御点と2次B-スプライン曲線の制御点は同一ではないと考えていた。
一方で、もしそのような折れ線を2次B-スプラインで表現できるのであれば、直線部分も2次B-スプライン曲線として表現可能になり、任意のTrueTypeアウトラインは制御点を挿入することなしに2次B-スプライン曲線だと言えるのではないかと思う。
B-スプライン曲線の定義
n次のB-スプライン曲線とは、制御点列(control points) とノットベクトル(knot vector)
とノットベクトル(knot vector) で定義される曲線である。曲線の補間(制御点の影響の計算)にはn次のB-スプライン基底関数が用いられる。
で定義される曲線である。曲線の補間(制御点の影響の計算)にはn次のB-スプライン基底関数が用いられる。
n次のB-スプライン基底関数(n-th order B-spline basis function)  は、次のように定義される。(コンピュータグラフィックス編集委員会(2004), p.66 (3.29)式)
は、次のように定義される。(コンピュータグラフィックス編集委員会(2004), p.66 (3.29)式)


これを使って、L個のセグメントからなるn次B-スプライン曲線は次のように定義される。

実際に描いてみた
プログラムを使って描いてみた。さすがに無限大は扱えないので適当に大きな値にしてみる。
描画に用いたPython3コードを次に示す*4。STEPが公比rに相当する。
gist.github.com
描画結果
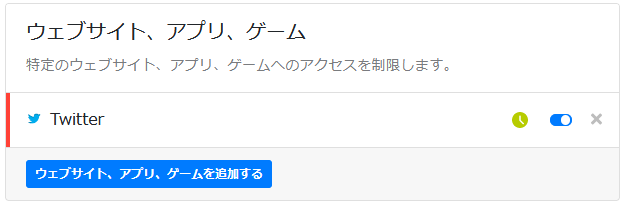
赤が正解となる1次B-スプライン曲線、黒が2次B-スプライン曲線である。
r=10
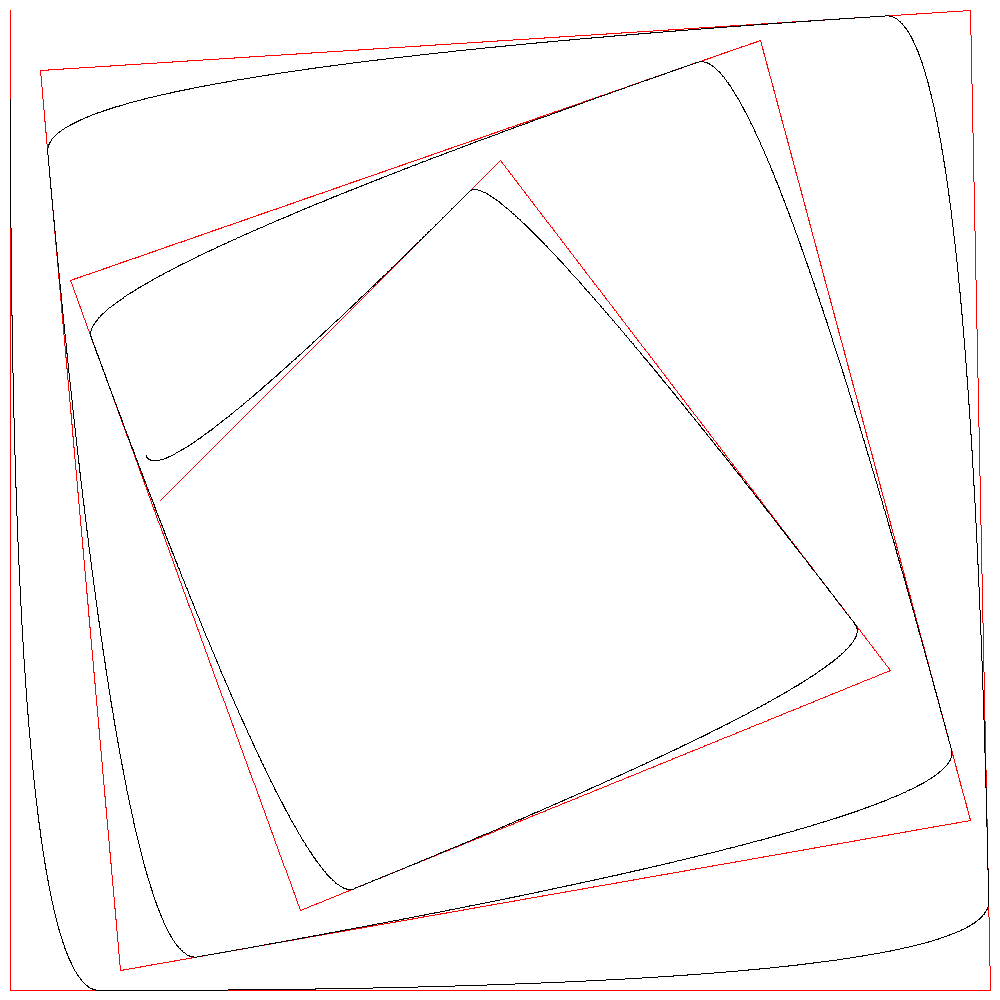
r=100
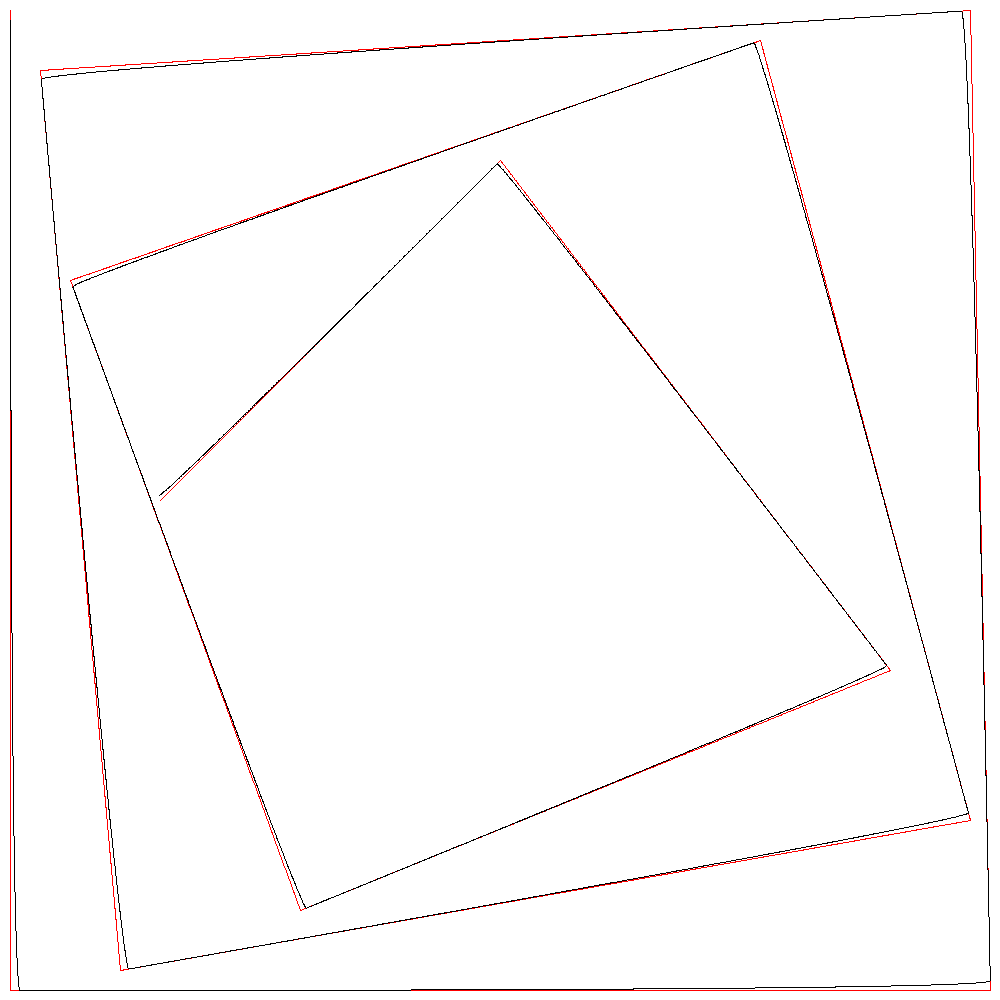
r=1000
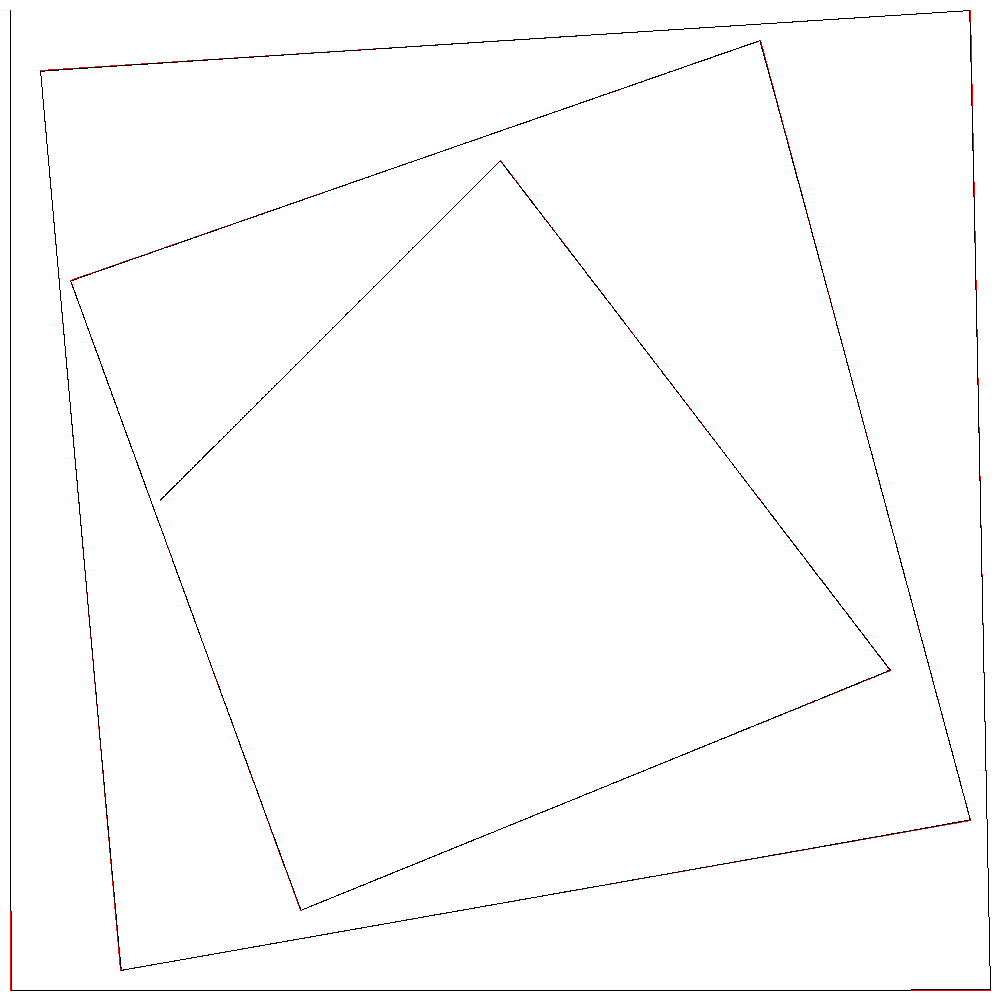
r=10000

r=10000でほぼ一致している。
隣り合う2制御点をr:1で内分する点を通る曲線が描かれているので、r=10000のときは2点を10000:1に内分する点を通る曲線となる。誤差が1ピクセルより小さくなるので直線に見えるというわけである。
画像サイズが(1000, 1000)なので公比r=10000程度でも直線になっているが、ドローソフトで線を拡大していく場合などはそれでも足りなくなると思う。
r=10000の場合、制御点15個に対して最初のノット値と最後のノット値を比べると1064倍になっている。複雑な図形にしたらすぐにあふれそう。
考察
1次B-スプライン曲線を(制御点を変更せずに)2次B-スプライン曲線を使って表現できる(そのようなノットベクトルの取り方が存在する)ことがわかった。
つまり、適切にノットベクトルを用意すれば、TrueTypeアウトラインのcontourをそのまま2次B-スプラインを用いて描画可能なのでは?
というわけで試してみる。
用意するのは次の制御点列。onはTrueTypeにおけるon-curve点、offはoff-curve点を示す。
| idx |
座標 |
on/off |
| 0 |
(10, 10) |
on |
| 1 |
(10, 990) |
on |
| 2 |
(250, 500) |
off |
| 3 |
(500, 990) |
off |
| 4 |
(750, 500) |
off |
| 5 |
(990, 990) |
on |
| 6 |
(990, 10) |
on |
| 7 |
(500, 500) |
off |
| 8 |
(10, 10) |
on |
これに対して、

みたいなノットベクトルを用意してみたらどうだろう。
r=10000として計算したのが次の画像である。この手法で計算された曲線が黒い線となっている。

制御点を青の点で示している。制御点列を結んだ直線が水色の直線である。
赤は正解となる2次B-スプライン曲線で、2連続するon-curve点の途中にその2点の中点をoff-curveな制御点として挿入してon-curve点の連続をなくし、ノットベクトルを[0, 0, 0, 1, 1, 2, 3, 4, 4, 5, 5, 6, 6, 6]としたものであるが、黒い線の下に入ってほぼ見えなくなっている。
描画に使用したPython3コードは次のものである。
というわけで、こんな感じのわけわからんノットベクトルを用意すれば、同一の制御点列を用いつつも2次B-スプライン曲線はTrueTypeアウトラインのcontourに一致する気がする*5。
ちゃんと計算すれば(上でやったのと同じような議論で)示せると思うけど面倒なので気になったら各自計算してね…
感想
無限大を導入すれば、任意のTrueTypeアウトラインのcontourの制御点列をそのまま2次B-スプライン曲線の制御点列として、同一のアウトラインを描けるノットベクトルの取り方が存在しそう、ということがわかった。無限大を導入すれば……
コンピュータで扱う数値計算に無限大を導入するな💢
実用としては素直に直線で計算するべし。