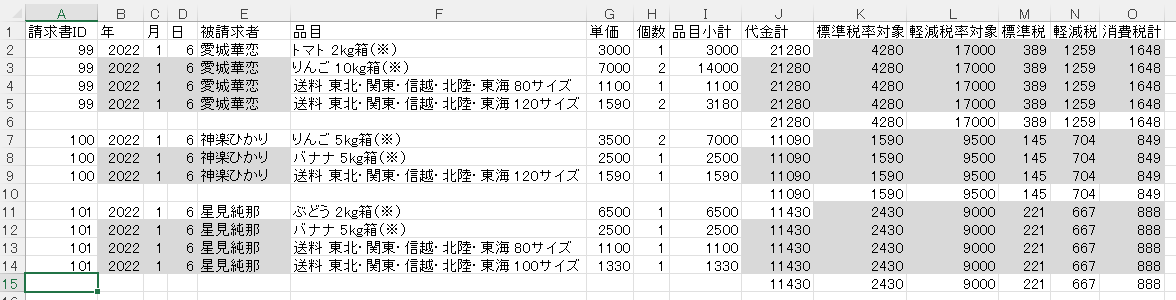
Otherwise, the initial invocation of Query only returns a NextToken , which can then be used in subsequent calls to fetch the result set. To resume pagination, provide the NextToken value in the subsequent command.
element = ET.fromstring('''<root><target name="Do's and dont's">some text</target></root>''')
target = element.find('''target[@name="Do's and dont's"]''')
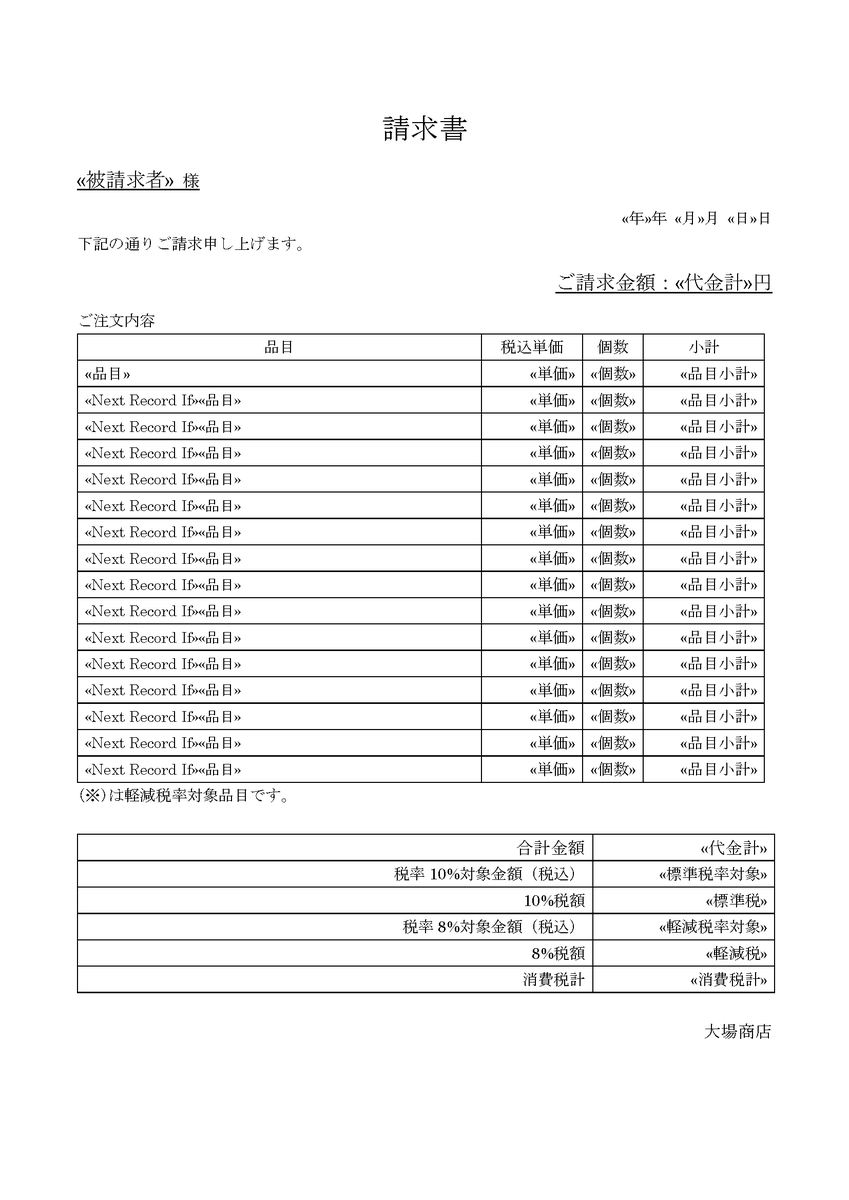
Next Record Ifというのがなぜ必要かというと、これがないと一つの請求書で1つの行しか参照せず、同じ品目が並ぶことになる。そのため、「次の行に進んでください」とWordに指示を出すコマンドが必要で、それがNext Record Ifである。ここでは「請求書ID」が空白でない場合のみ次の行に移るように設定したので、空白行より先には進まないでそこで止まる。