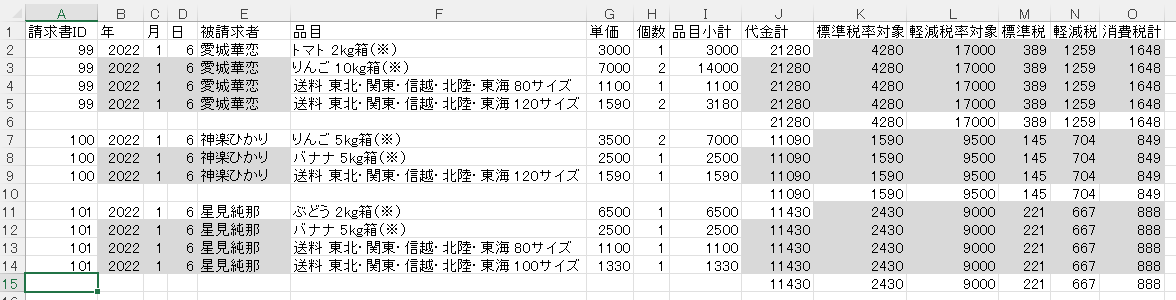
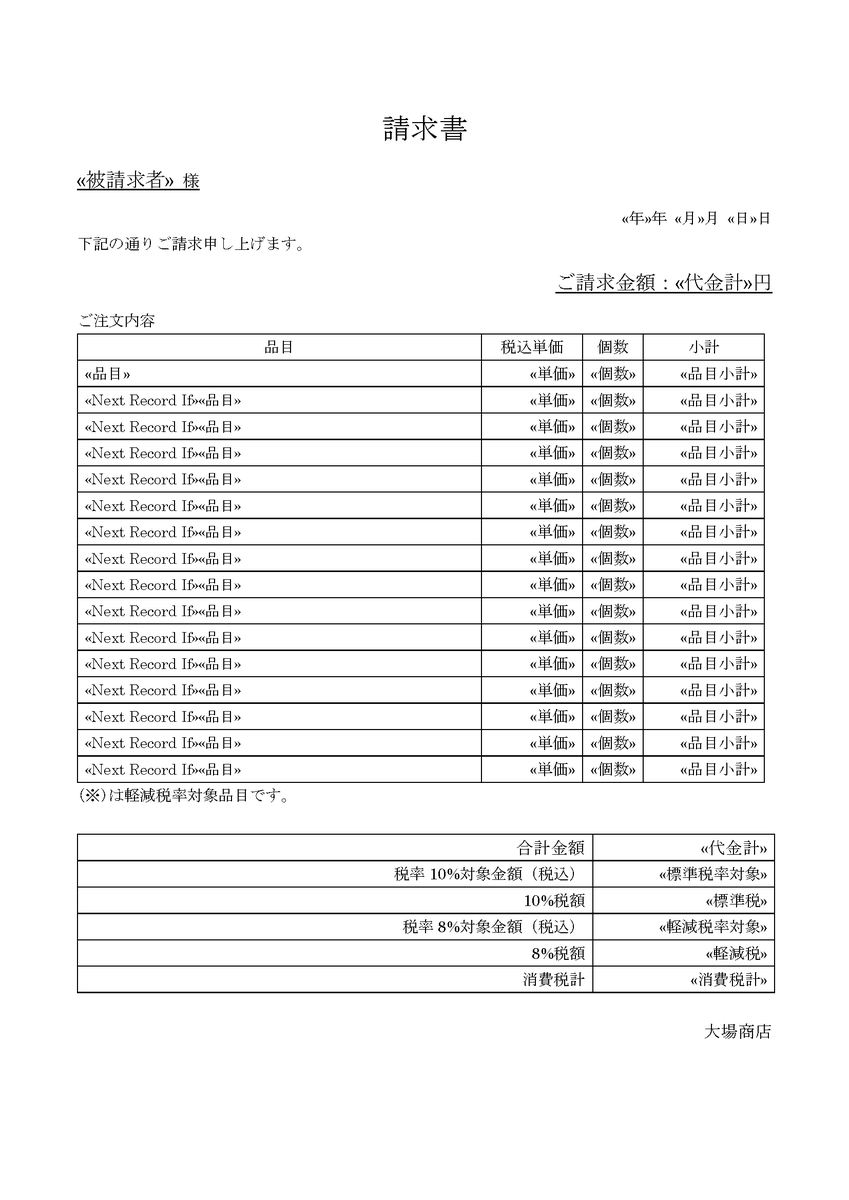
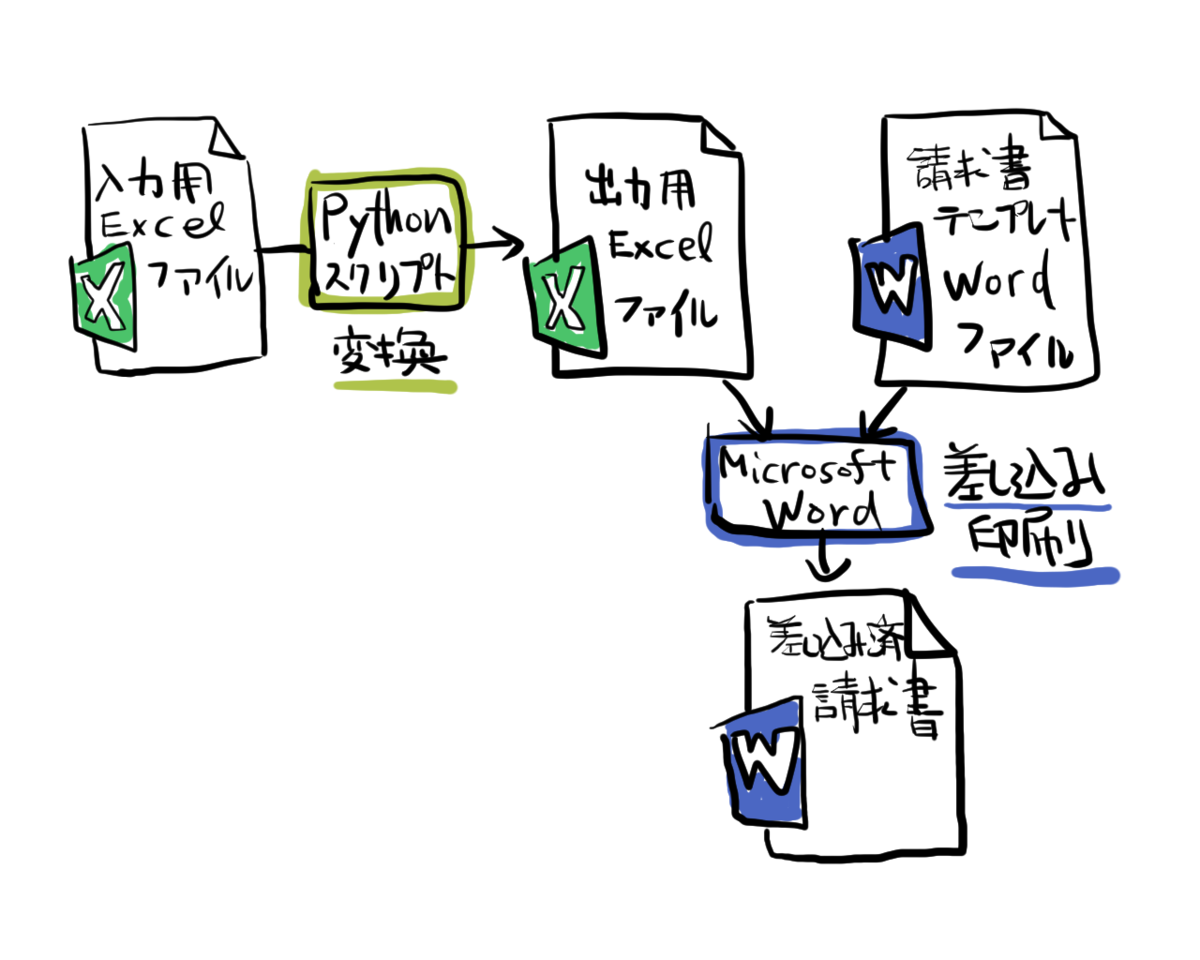
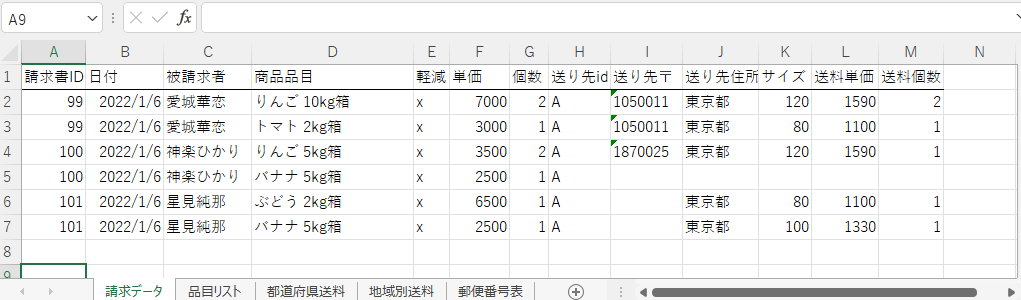
Private Reserve社のインク
Private Reserve社という、万年筆インクを製造している会社があった。
その会社が製造するインクは発色がよく、染料インクなので扱いやすく、混色も可能というものだった。
そのため、自分で好みの色のインクを調合できる店であるカキモリのInkstandにおいて、混色用のインクとして2017年頃まで使われていた。しかし、安定した入手が困難になったため、現在は独自の顔料系インクに切り替わっている。
入手困難だった理由
なぜインクが入手困難になったのか?
https://www.fountainpennetwork.com/forum/topic/355755-private-reserve-ink-status/
このフォーラムを追っていくと経緯が書いてある。フォーラムの記載によると、次のようなことがあったらしい。
まず、元々の会社のオーナーが逝去したとのことで、そのためインクが生産できなくなった。新しく生産されないため、在庫がなくなると入手困難状態になっていた。
その後、従業員であったDarla Aniline氏が2018年にPrivate Reserve社を購入し、一人会社として運営されていた。インク調合のレシピがほとんど残されていなかったので再生産が難しかったという事情もあり、配合を再現しようと化学者と共同して作業していたらしい。しかし、2020年9月にAniline氏も早逝。会社は機能停止したことになる。
新しいPrivate Reserve Ink
さて少し経って、Cult Pensという文具ショップのFacebook投稿によると、2021年3月に元々のものと同じレシピ(the original formula)で新しく製造・販売が開始されたとのこと。
私が気づいたときにはCult Pensで在庫切れになっいたが、その後在庫が復活したので、2021年8月にインクを購入した。



箱には製造者については書かれていないが、ヨーロッパで製造、アメリカで包装とあり、また www.PrivateReserveInkUSA.com というアドレスが書かれている。これにアクセスすると yafabrands.com のページにリダイレクトされる。これはYafaというアメリカの筆記具会社らしい。
探すとYafa社がPrivate Reserve社を買収したと書かれているPDFがあった。
https://www.yafa.com/outlet/images/Pen_world_article.pdf
というわけで、2021年3月ころからYafaブランドの元で新しく製造されたPrivate Reserveインクの流通が始まったらしいことが分かった。当分の間は安定した供給が見込めそうである。とりあえずは一安心という感じだ。
購入方法
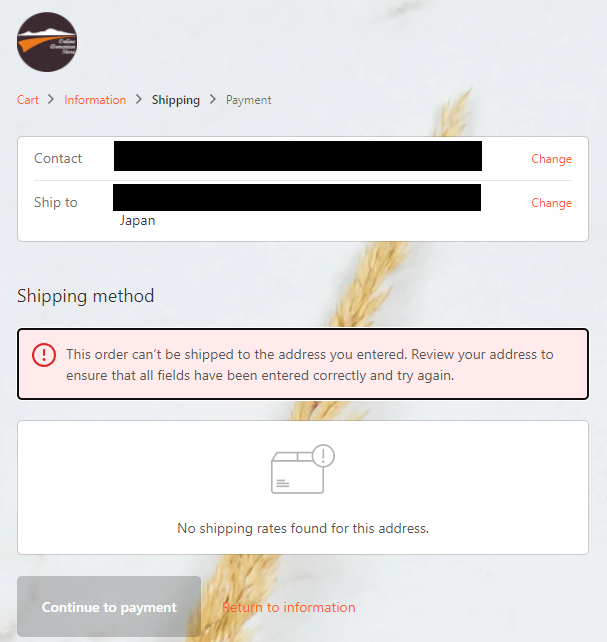
日本からも、CultPensなどの日本へも配送してくれるネットショップで購入できる。しかし、私が2021年8月に購入した時は3つのボトルを購入して送料が1500円程度(恐らく14~15 USD)だったものの、現在購入しようとしたら安い運送方法の選択肢がなくなって5800円程度(たぶん50 USD)はかかるようで、躊躇している。
Ebayとかで購入する方が配送料が安い(3千円以内)っぽいので、今はそっちで購入するのがいいのかもしれない。もうちょっと円が強いときに買いたいが…。
ところで、私が混色に使っていたFoam Greenというインクを含む数色が、新体制では製造されなくなってしまったらしく、手元で今までと同じ色のインクを調合することが難しくなってしまった。別のインクを使って近い色にできるように試行錯誤しなければならない。まあそれは追い追い。
おまけ

Cult Pensでインクを購入した時、“This is a pencil.”と書かれた鉛筆がおまけに付いてきた。すき。

2023-01-02追記
日本Amazonにあるじゃん!例→https://www.amazon.co.jp/-/PR17019/dp/B0B2MTLK7Z/
「Private Reserve Ink」や「プライベート リザーブ インク」などで検索してみてください。