まえがき
ミャンマーでは公用語としてビルマ語が使われている。ビルマ語の表記にはビルマ文字を用いるのだが、このビルマ文字のインターネット上での使用は、混迷を極めていた。そしておそらく今もまだ…。なぜか?
それは、Unicodeという文字コードの標準がありながら、Zawgyiというものが広く使われていたためである。なぜそのようなものが登場し、普及することとなったのか、この記事で解説する。
目次
凡例
この記事で使う名称について
ミャンマーという国は、1989年に公式の英語名称でBurmaではなくMyanmarという語を使うように変更した。BurmaとMyanmarはどちらもビルマ族の自称(バマーဗမာとミャマーမြန်မာ)に由来するもので、それぞれ口語体と文語体のものであり、いずれも普通に使われている。
この記事では便宜的に、「ミャンマー」という国の主要な民族である「ビルマ族」の言語を「ビルマ語」と表記し、ビルマ語表記のための文字を「ビルマ文字」とする。
また、ビルマ語以外のミャンマーの諸言語(シャン語、カレン語など)もビルマ語と近い文字を使うが、これらのミャンマー(および近隣)の言語を表記する文字を総称して「ミャンマー文字」と称することにする。
Zawgyiの概説と歴史
Zawgyiとは
Zawgyiは、ビルマ語表記のためのフォントで、ゾージーと読む。Zawgyi font, Zawgyi-Oneなどとも書かれる。
おそらくビルマ文字ではဇော်ဂျီと書き、発音が/zɔ̀d͡ʑì/である語だと思われる。ヨガをやる人ってことらしい?
Zawgyi誕生・普及の経緯
この節はブログ記事Battle of the fonts | Frontier Myanmarを元にしている。
複雑なビルマ文字
ビルマ文字はインド系文字の一種であり、複雑な用字系*2である。複雑な用字系とは、ある1つの文字が前後の文字に応じて様々に形を変える、文字が発音される順番に並ばない場合がある、などの要素を持つ文字体系である。
ビルマ文字とUnicode
Unicodeには、1999年のバージョン3.0でビルマ文字が収録された。
Unicode以前にビルマ文字の符号化標準が作られたことはなく、そのため、それ以前はコンピューター上で扱うのは困難だったか、可能でもビルマ文字テキストデータを不特定の人とやりとりすることは不可能に近かったと思われる*3。
Unicode標準に入ったため、ビルマ文字の文字列を一通りのコード列にすることは可能になったものの、Unicodeのビルマ語を正しく表示するための技術は、2005年まで存在しなかった。これは、複雑な用字系を扱うための技術的困難に起因している。
一方では西欧諸国による制裁などもあり、自国で複雑な仕組みに対応するシステムを開発する能力もなかったことから、当面の間は自分の国で何とかなる仕組みでミャンマー文字をコンピュータで使えるようにしようと、暫定的な回避策が開発された。実用できない標準より、とりあえず表示はできる非標準の方がいいだろう、ということだと思われる。
これはUnicodeやコンピュータのUnicode対応が成熟するまでの繋ぎのつもりだったようだ。
回避策としてのビルマ文字フォントの登場
まず、Ko Ngwe Tun氏がMyazedi*4というビルマ文字用フォントを作り、販売した(2003年ころと思われる)。これは、Unicodeのミャンマー文字ブロックにビルマ文字を収録していたが、一つの文字に形状のバリエーションがある場合、それらを別々のコードポイントに割り付けていた。部分的にはUnicodeと共通している部分はあるが、互換性はない。
非標準ではあるものの「とりあえず表示できる」フォントの最初期の実装であったが、プロプライエタリであり高額(ユーザーライセンスがUS$100、コンテンツを作る会社にはUS$1,000)だったため、広くは普及しなかった。
Zawgyi-One(あるいは単にZawgyi)フォントは2006年にフリーウェアとして登場した。Myazediをパクったとみられ、最初のバージョンにはKo Ngwe Tun氏の著作権表記の一部がそのまま含まれていたらしい。無料であることから、だんだんMyadeziを置き換えつつ、一般に普及していった。
ある時、Ko Ngwe Tun氏の会社が、Myazediの海賊版フォント(= Zawgyi)を使用した会社やZawgyiの開発者たちを訴えると発表した。これを受けて、Zawgyiの開発者たちはパクリだとみなされないように改変を加え、Myazediとの互換性をなくすとともに、Unicode標準からさらに離れることとなった。
その間Unicode方面はどうなっていたかというと、2005年にWindows XPでUnicodeビルマ文字の表示が可能になってからは、Unicodeフォントが作成された。だが完全なものではなく、扱うのに技術的な知識が必要だったりしたため、Unicodeは普及しなかった。また、2008年のUnicode 5.1で後方互換性のない大きな変更がなされるまでミャンマー文字ブロックは大幅な見直しが行われていて、エンコードが安定していなかった*5。
Zawgyiの普及
その後のZawgyiのリリースにおいて、一般ユーザーにはインストールは簡単だが、アンインストールが困難な形態のものが登場した。例えば、Arialフォントを書き換えたり、アンインストール方法のないInternet Explorerプラグインとして提供されるなど。
ネット上のほとんどがZawgyiによって書かれているものとなったため、新しくコンピュータを買った人はZawgyiをインストールしたし、 一般に売られるスマホも、最初からZawgyiがインストールされた状態で提供された。
このように、事実上の標準となったZawgyiにロックインされてしまい、Unicodeへの移行は困難になっていた。
2019年に国が正式にUnicodeに切り替えるぞ!と言うまでは広く広く使われていた。それからはだんだんUnicodeが普及しているらしい。
Zawgyiの実装
Zawgyiは、Unicodeのインド系文字で使われている複雑なレンダリングの仕組みを回避するものであるため、実装は単純である。
子音字・独立した母音字などはUnicodeと共通している。Unicode 5.0以前に存在していたビルマ文字については、同じ文字が当てられているように見える。そのほかに、下に重ねて書く子音字や、記号類のバリエーション、合字などが追加されている。
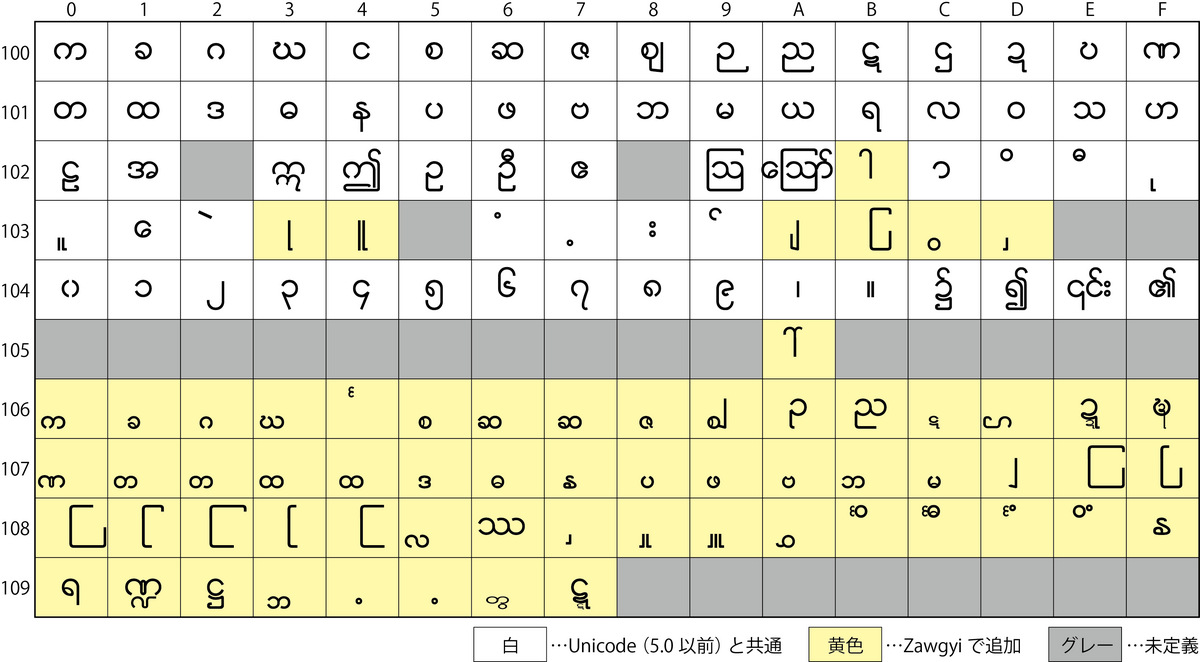
上図がコード表であるが、白色部分がUnicode 5.0以前と共通の文字であり、黄色部分はZawgyiで独自で割り当てた文字である。
実装の方針
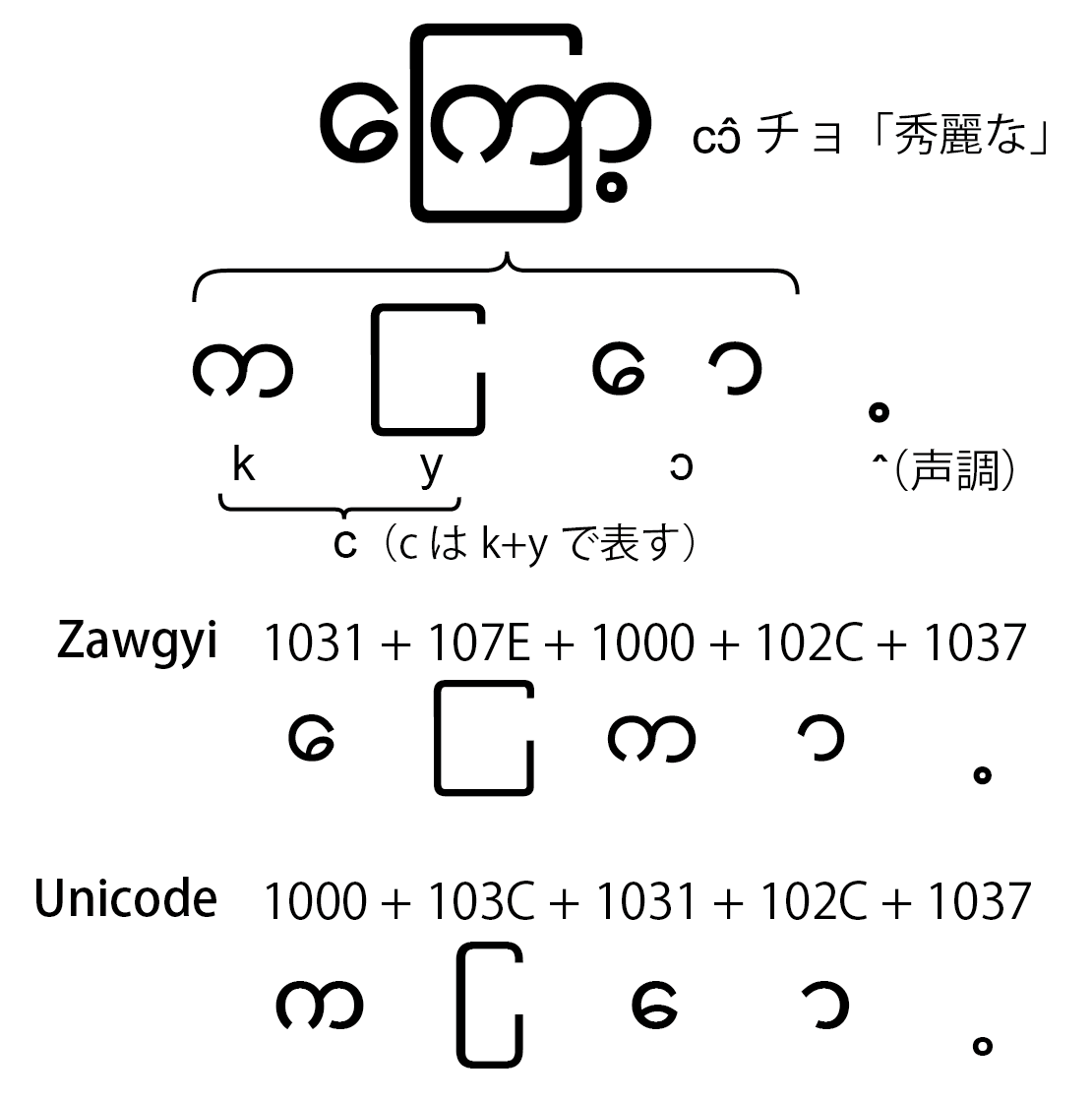
文字の並べ替えをせず、左から右に書く
Unicodeでは、できるだけ発音順に文字をデータとして収録する方針をとっており、そのため表示する際に文字を並べ替える必要がある。
Zawgyiでは、並び変えの必要をなくし、左から順番に並べていくだけである。
次図に「秀麗な」という語のZawgyiとUnicodeでの表現の比較を示す。Zawgyiでは見た通りに文字が並べられ、Unicodeでは発音する順に並べられているのがわかると思う。
文字の形のバリエーションに対して、別々のコードポイントを割り付ける
Unicodeでは、一つの文字が前後の文字によって様々に形を変える場合、その文字のバリエーション一つ一つに別々のコードポイントをあてることはせず、一つのコードポイントの文字を、プログラムやフォントの機能を使って形を替えることで対応するのを基本としている。
Zawgyiでは、文字の形のバリエーションや合字に対して、すべて別々のコードポイントを割り付けている。これにより、前後の文字に応じて文字の形を変更する必要がなくなり、プログラムやフォントの変形への対応が不要になる。

顕著な例としては、介子音記号のraは、子音字をぐるっと囲むような記号であるが、
- 幅が狭い文字に付く場合/広い文字に付く場合
- 上に記号が来ない/来る場合
- 下に記号が来ない/来る場合
の場合分けにより、8通りの形が収録されている(上図)。
Unicodeミャンマー文字の実装
さて、Unicodeの複雑さを回避するためにZawgyiが出てきたことを考慮すると、なぜZawgyiが普及するに至ったかを考えるのには、Unicodeによる符号化がどんなであるかを見ていく必要があるだろう。
Unicode登場まで
Unicodeは、それまでに存在していたテキストエンコーディングを置き換えることを意図して作られた。そして、レガシーな文字コードとの相互運用性を重視していることから、Unicode以前からある既存の文字コードの標準や、広く通用したデファクトスタンダードな文字コードは尊重される。
このため、ビルマ文字の文字コードが存在していれば、それに近い形でUnicodeにビルマ文字が入ったはずである。
しかし実際には、Unicode以前にビルマ文字の標準的な文字コードが作られたことはなさそうで、1999年にUnicode 3.0で実装されたのが初めてのビルマ文字の符号化標準であった。
従って、デーヴァナーガリーなどの他のインド系文字の方式を参考に、新規に標準が作成されたと思われる*7。
論理順
インド系文字の符号化にかかわってくるUnicodeの原則として、論理順がある。
論理順の原則というのは、かんたんに言うと、文字を、発音する通りの順番でデータとして収録するという原則である*8。
例えば、インド系文字では子音字の上下左右に母音記号がつき得るのだが、子音→母音の順に発音されるのだから、母音記号が子音字の左に書かれる場合でも、データの上では子音字→母音記号の順に収録し、表示する際に母音記号が子音字の左側に来るように並べ替えるというものである。

一例として、ပြေလည် pyèlɛ̀「うまくいく」という単語を見てみると、Unicodeでは上図のようにp-y-èの順番のデータとなるが、見た目の順番では左からè-y-pの順に並んでいて、論理順と視覚順で順番が異なっている。
これにより、データの上ではきれいで、ソートなどもやりやすくなるのだが、表示するときには文字の入れ替えをしなければならない。この文字の入れ替えに関しては、テキストレンダリングエンジン……つまりテキストの表示に用いるプログラムが責任を持つ。そのため、対応していないプログラムを使った場合、正しく表示されないということになる(上図の「間違った表示」参照)。
ブラウザなどでの対応はずいぶん良くなったものの、これに対応していないソフトウェアや、設定で有効になっていなかったりして、正しく表示されないという事態は多々発生している。
話はややずれるが、ビルマ文字を手で書くときは基本的に左から右、内側から外側に書くので、上のpyèlɛ̀の例では、è-p-yの順番で書くことになる。これは論理順と異なっているが、コンピュータでの入力の際には、手で書くような順番で入力すると、インプットメソッドがUnicodeとしていい感じのコード列に変換してくれたりするようだ。
グリフでなく文字
また、Unicodeの原則として、グリフでなく文字を収録するというものがある。
ここでいう文字(character)とは、様々な形のバリエーションがあっても同じ字だと認識されるようなグループに関して、抽象化した文字を想定したものである。一方、グリフは文字の具体的な図像表現であり、文字が目で見える形になったものがグリフである。同じ字でもフォントによってデザインが違うが、それらはグリフの違いであり、文字の違いではない。
これはつまり、一つの文字は原則として1つのコードポイントに割り付け、形のバリエーションは独立して収録しないというものだ。そのため、ある文字が文字の位置や前後の文字などに依存して形が変わる場合、変形後の形はUnicodeに独立して含まれないのが原則であり、表示時にそのような別形への変換を行う必要がある。
これを実現するには、別形へと置換する情報をフォントに含めて、テキストレンダリングエンジンからその情報を参照して置き換えを行うことで可能となる。要するに、フォントとテキストを描画するプログラムの両方が対応していないと、正しく表示することができない。
インド系諸文字でこれが関わってくるのが、ヴィラーマモデルである。
ヴィラーマモデル

インド系文字は音節文字であり、子音字は基本的には母音とセットになった状態で書かれる。ヴィラーマ(virama)は、子音字につけられて、母音がないことを示す記号である*9。ヴィラーマはサンスクリット語における呼称であり、各言語によって呼ばれ方は異なるが、Unicodeでは基本的にすべてヴィラーマと呼んでいる。
ビルマ文字におけるヴィラーマはやや特殊なため、ここではインド系文字の一つであるデーヴァナーガリーを例として説明する。
デーヴァナーガリーには、ヴィラーマ記号の他に、母音をなくす表現として、半子音字と呼ばれる仕組みがある。次図に例を挙げる。これは子音字の一部を欠いたものであり、次の子音と連続して、子音連結として発音される場合に用いられる。

Unicodeでは、この半子音字に独立したコードポイントを当てるのではなく、子音字+ヴィラーマの組み合わせで表現する。このように、子音字のバリエーションなどをヴィラーマを組み合わせることで表現するのがヴィラーマモデルである。
すべての子音字について対応する半子音字が存在するわけではなく、子音の組み合わせによっては縦に重なったり特別な合字で表されるものもあるが、次図のように同様にヴィラーマを利用して表現される*10。

ビルマ文字の場合
さて、ビルマ文字の場合を見てみよう。

ビルマ文字でヴィラーマに相当する記号はasat (အသတ် /ʔat̪aʔ/ アタッ)である(上図)。しかし、これは母音・末子音・声調などを表すために他の文字と組み合わせて書かれ、母音がないことを示すヴィラーマとは少し性質が異なった使い方がされている。単語の綴の中に含まれていて、後ろに文字が続くからといって書かれないということはない。
現在のUnicodeでは、asatには独立したコードポイントが与えられているが、Unicode 5.0以前ではそうではなかった。これについては次の章でも説明する。
また、ビルマ文字では縦に子音字を重ねることがある。これは主にパーリ語などのインド系言語からの借用語にのみ現れ、借用元の言語で子音連続となっている部分を上下に重ねて書く。次図に例を挙げる。

Unicodeでは、この重ね文字は、子音字等と子音字の間にヴィラーマを挟むことで表現される。
この重ね文字については、フォントに文字の形を変えて積み重なるようにする情報を含め、表示を行うプログラムからそれに基づいて描画する必要がある。
Unicodeでのミャンマー文字の扱い方については、Unicodeが公開するFAQがあったり、UTN #11 "Representing Myanmar in Unicode"に詳細があるので、詳しくはそちらを参照されたい。
最後に、စင်္ကြံ zínjàn「歩道」とသင်္ဘော t̪ínbɔ́「船」という例を次図に挙げてこの節を終わる。データは論理順に並んでいるが、表示順からは想像できないような順番になっているのがわかると思う。

参考
- The Unicode Standard Version 15.0 - Core Specification. “2.2 Unicode Design Principles”. pp.14-24. URL: https://www.unicode.org/versions/Unicode15.0.0/ch02.pdf
- Unicode Cnsortium. FAQ - Myanmar Scripts and Languages. URL: https://www.unicode.org/faq/myanmar.html
- Martin Hosken. Representing Myanmar in Unicode. Details and Examples Version 4. (UTN #11 v4) URL: https://www.unicode.org/notes/tn11/UTN11_4.pdf
Unicode 5.0.0と5.1.0の比較
ビルマ文字はUnicode 5.1.0で大きな変更があってからは、互換性が壊れるような変更は行われず、安定していると思われる。この章では、バージョン5.0.0と5.1.0との間でのビルマ文字に関する差異を見ることで、Unicodeのビルマ文字エンコーディングがどう変化したかを概観する。なお、ここではビルマ語以外のために追加された文字については取り上げない。
基本的な変化としては、以前はフォントによる置換で対応していた変化形の一部に独立したコードポイントが当てられ、よりプログラムやフォントの実装がやりやすくなっているように思われる。
asatへの独立したコードポイントの割り当て
5.1.0でasat (အသတ် /ʔăt̪aʔ/ アタッ)に独立したコードポイントが割り当てられた(U+103A)。それまではvirama U+1039 + ZWNJ U+200Cで表していた(Unicode Standard, Version 5.0のp.380など参照)。
例1: ကော် /kɔ̀/
| Version | Unicode表現 |
|---|---|
| 5.0.0 | U+1000ka + U+1031vowel sign e + U+102Cvowel sign aa + U+1039virama + U+200CZWNJ |
| 5.1.0 | U+1000ka + U+1031vowel sign e + U+102Cvowel sign aa + U+103Aasat |

virama + ZWNJでヴィラーマに相当する文字を表示するのはヴィラーマモデルでは典型的な挙動であり、デーヴァナーガリーなどではそうなっている。ただし、ミャンマー文字のasatは次に子音字が後続しようが常に表示されるものであり、母音や末子音や声調などを表すために非常に頻繁に用いられる。そのため、これが1つのコードポイントだけで表現できるようになったことで、かなりの効率化が図れたと思われる。

介子音記号への独立したコードポイントの割り当て
介子音記号は、「virama + 子音字」の組合せから、個別のコードポイントが割り当てられるようになった。
| 文字 | Unicode 5.0.0表現 | Unicode 5.1.0表現 |
|---|---|---|
| 介子音記号ya | U+1039virama + U+101Aya |
U+103Bmedial ya |
| 介子音記号ra | U+1039virama + U+101Bra |
U+103Cmedial ra |
| 介子音記号wa | U+1039virama + U+101Dwa |
U+103Dmedial wa |
| 介子音記号ha | U+1039virama + U+101Fha |
U+103Emedial ha |

これにより、形状の置換を減らせるのでフォントの実装がシンプルになるとともに、入力する側としてもより直観的なデータ表現になったと思われる。
縦長のaaへの独立したコードポイントの割り当て
ビルマ語では、縦長のaaは、普通の丸いaa ( ာ U+102C)が来ると紛らわしくなる場合に用いられる(例: ပါ /pà/ ↔ဟ /h/を表す子音字)。
aa (長母音a; ာ U+102C)の縦長版は直前の文字に応じてフォントで形を変えることになっていたが、独立したコードポイントが割り当てられた( ါ U+102B)。

これについては、スゴー・カレン語(S'gaw Karen)の正書法においては縦長の形しか用いられないため、それへの対応として分離されたようだ(Unicode 5.1.0のミャンマー文字の節参照)。
とはいえ、ビルマ語で使い分けがどのようにされているのかは自明ではないかもしれない。ミャンマーで出版されたあるビルマ語辞書のဓ dhaの項目を見たところ、次にaaが来てဓာとなるものと、tall aaが来てဓါとなるものとが並んでいた(次掲の写真参照)。

単に好みで形を選んでいるのか、何らかの区別を行っているのかは、私は知識がないのでわからないが…。この辞書を文字の形をそのまま電子化するには、古い方式では難しかったかもしれない。
aforementionedの扱いの変更
၎ U+104E aforementionedの扱いが変更された。
以前はU+104E単独で၎င်း lăgáuɴという語全体を表していたが、5.1.0ではlăgáuɴの最初の部分၎だけになった。
この字は၎င်း lăgáuɴという語にしか使用されない*12ものの、lăgáuɴの別表記で、င်္၎ (င်が၎の上につく)という形に対応するためにこうなったらしい(UTN #11 v4のp.11参照)。
これにより、lăgáuɴのエンコーディングが次のように変更になった。
| Version | Unicode表現 |
|---|---|
| 5.0.0 | U+104E aforementioned |
| 5.1.0 | U+104E aforementioned + U+1004 nga + U+103A asat + U+1038 visarga |

great saへの独立したコードポイントの割り当て
သ U+101E saが2つ重なる時は、great sa ဿという特別な形が使われるのだが、これに独立したコードポイントが割り当てられた。
| Version | Unicode表現 |
|---|---|
| 5.0.0 | U+101E sa + U+1039 virama + U+101E sa |
| 5.1.0 | U+103F great sa |
これに並行して、古いシーケンスはသ saが規則通り縦に重なる形に変更になっている: သ္သ

参考
- The Unicode Standard, Version 5.0. “11.3 Myanmar”. pp.379-381 (紙面上). URL: https://www.unicode.org/versions/Unicode5.0.0/ch11.pdf
- Unicode 5.1.0. URL: https://www.unicode.org/versions/Unicode5.1.0/#Myanmar
- The Unicode Standard, Version 5.0: Archived Code charts. “Myanmar”. pp.97-98. URL: https://www.unicode.org/Public/5.0.0/charts/CodeCharts.pdf
- The Unicode Standard, Version 5.1: Myanmar (Versioned Code Chart). URL: https://www.unicode.org/charts/PDF/Unicode-5.1/U51-1000.pdf
- Martin Hosken. Unicode Technical Note 11 - Representing Myanmar in Unicode: Details and Examples. Version 4. URL: https://www.unicode.org/notes/tn11/UTN11_4.pdf (UTN #11 v4)
Zawgyi/Unicode判定・変換プログラムについて
Facebookなどでは、Zawgyi/Unicodeを自動判定し、ユーザーの環境に応じて変換しているらしい(参考: ミャンマー語(ビルマ語)のフォントがZawgyiからUnicodeへ大改革 - Enjoy Yangon ヤンゴン, ミャンマーで暮らす旅する)。
Zawgyi/Unicodeの判定、および変換をするプログラムやライブラリは複数ある。
一例をあげると、Googleが公開している次のものがある。
このプログラムでは機械学習を用いて判定を行っている。理由としては、人の手でルールを記述することでZawgyi/Unicode判定を行う場合では、本来のUnicodeでシャン語やモン語などが書かれている場合を誤判定してしまうことがあるためだとしている。
つまり、ビルマ語だけを判定するのでよければ、人の手でルールを記述すれば十分な精度が得られることはあるようである。母音の並び順、Unicodeのビルマ文字以外の符号位置の利用などを見るだけでも、十分な長さがあればそれなりの精度で判定はできそうだ。とはいえ判定ルーチンを自分で書くことはまずないと思う。
また、変換に関しては変換ルールを書いていけばいいのだが、前に上げたzínjànやt̪ínbɔ́というような語などZawgyiとUnicode間の順番が大きく異なるのもあり、漏れなく変換ルールを書くのが難しい。
そのため、既存の実績のあるツールやライブラリを使うのがよいと思う。
まとめ
Unicodeに収録されたミャンマー文字をコンピュータで正しく表示することが困難だったために、その表示上の複雑さを回避するZawgyiフォントが作られ、それがデファクトスタンダードとしてミャンマーで広まってしまった。そのため、グローバルスタンダードであるUnicodeへの移行が困難になっていた。
この先Unicodeが普及していくにしろ、過去の資産としてZawgyiで書かれたテキストデータが大量に存在するため、これを無視することができない。判別プログラムを使って判定し、必要に応じて変換を行うことが肝要だろう。
*1:おそらくUnicodeの文字名はビルマ文字のラテン文字転写に由来するものと思われるが、ミャンマーで公式に採用されているラテン文字転写はパーリ語向けのものを元に作られているようで、ビルマ語の音韻構造を表してはいない。そのため、ある程度文字の区別が可能である一方で、転写から発音を想像することが困難になっている。参考: MLC Transcription System - Wikipedia
*2:Complex script. 「用字系」はscriptの訳で、文字の体系のことを示している。scriptは単に「文字」と訳されることがある(例: ビルマ文字/Burmese script)が、個々の文字(letter)と区別するために用字系と訳されていると思われる。
*3:8ビットコードの範囲内(ASCIIや、Latin-1の範囲)にビルマ文字を割り当てたフォントが使われていたらしい。ただし、フォント毎に文字の配列が異なるので、フォントを変えると文字化けしたとのこと。参照: ビルマ語(ミャンマー語)をWindowsで~Unicode以前 | エヤワディ Blog
*4:Myazediという名は、1112年に刻まれたとされるミャゼーディー碑文に由来するものかもしれない。これは現在知られている限りビルマ語最古の碑文であり、パーリ語、ピュー語、モン語、ビルマ語の4言語で碑文が刻まれているため、ミャンマーのロゼッタストーンとも呼ばれる。参考: ミャゼディ碑文 - Wikipedia
*5:Unicodeミャンマー文字がほとんど使われてなかったから互換性のない変更を行うことが可能だったわけで、エンコードが安定していないのが普及しない原因だった訳ではなさそうだ。
*6:advance width. 次の文字を表示する位置がこれだけ進行方向前方にズレる、という幅。
*7:インドの諸文字やスリランカのシンハラ文字、タイのタイ文字などはそれぞれの国によって文字コード標準が作成されていて、それをもとにUnicodeへと収録されたようだ。ミャンマー文字は、仕組みが似ていて当時標準が存在していなかったクメール文字とセットで、新規にUnicode標準策定が行われたようである。
*8:原則というのだから例外があり、例えばタイ文字なんかは論理順でなく表示順で左から右に並べるものになっている。これは、Unicode策定時にTIS-620というタイ語の文字コード標準が存在していたため、それがそのままに近い形でUnicodeに入ったということのようだ。
*9:ヴィラーマは無母音記号だと説明したものの、どちらかというと母音をなくす概念の名前かもしれない。サンスクリット語に関する知識がないので詳しくはわからないが…。参照: Virama - Wikipedia
*10:サンスクリット語、ヒンディー語など、言語によって子音の組み合わせに対する合字の形や使い方が異なるため、フォントは言語毎に別の設定を行う必要があるようだ。参考: 『電脳社会の日本語』:ほら貝
*11:kinziは最初入力方法がわからなかった。独立したキーを当てるとかしないと初見では入力無理なのでは…。
*12:၎ U+104Eのこの形は元々はビルマ数字の4 “၄”に由来するが、これは数字の4の発音とlăgáuɴの最初の発音が当時同じだったために、最初の部分を数字の4で代用した略記がなされ、広まったとのこと。発想は英語スラングの2nite (= tonight), 4get (= forget)とかに近いようだ。参考: ၎င်း - Wiktionary, the free dictionary